Clustering Factor and its Effects on Optimization in SQL

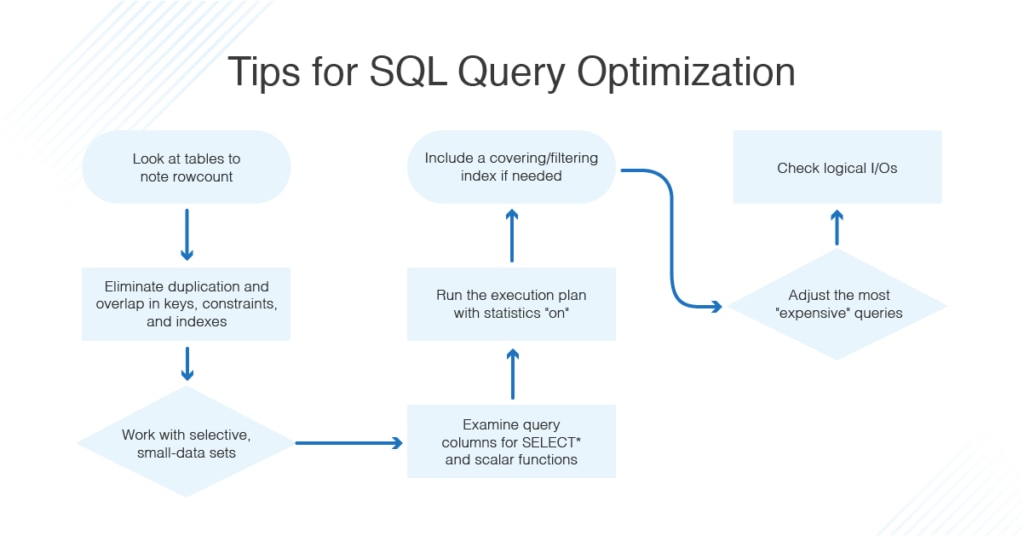
The
clustering factor refers to a numerical value that denotes the extent of random
data distribution in a table. To define it simply, it is the number of times a
block changes when an index is in use for reading a table. It has a role of its
own to play during optimization in SQL.
Another way
to explain this term is to call it a measure of how sorted an index is as
compared to the table it’s based on. Its main use is to find an estimate for a
table lookup after index access. The cost of the operation is usually
calculated by multiplying the selectivity of the index with the clustering
factor.
A high
clustering factor typically implies that the table doesn’t have its rows in a
proper sequence. This will lead to excessive I/O consumption during extensive index
range scans, hence requiring the user to performance
tune SQL query. Calculating the clustering factor, at the time of index
stats collection involves the following steps by Oracle:
● Oracle draws
comparisons between the row id block and that of the last index entry. It does
this for each entry.
● In case
there is a difference when the comparison is made, the database increases the
clustering factor by one.
The least
possible value of the clustering factor is equivalent to the number of known
blocks that were located from the index’s list. For example, the clustering
factor for an index on one or more columns without nulls is normally the number
of blocks that hold data. On the other hand, the greatest possible clustering
factor would be the number of index entries.

Interpreting
the clustering factor enables the DBA to estimate the number of table blocks
involved in an index scan. This value also becomes useful later during optimization
in SQL. If its value is somewhere near the index entry quantity, you can
safely assume that a thousand-entry index scan might need to read around a
thousand blocks from the table.
In another
example, if the clustering factor is almost as high as the number of table
blocks, the same magnitude of index scan could only require fifty blocks
instead. You may compare it with the cost of one complete table-read to the high-water
notch to find which type of scan is more efficient. You can use the multiblock
input-output mechanism to find a winner between an index range and a full-table
scan.
It is
important to observe the number of large deletes made from the table. This is
because such operations leave blocks empty of rows in many cases. The
clustering factor takes these into account since these blocks are not about to
show up in the index list. However, a complete table scan is still going to
read every table block without considering if the block contains rows or not.
This is why,
in extreme instances, the database might detect that reading a huge table with
a million blocks entirely may only need it to read ten of those blocks. It can
make an estimate of the number of blocks it has to read by going through the
table and index statistics.
Given the
presence of NOT NULL constraints informing the database about every table row within
the index, an index scan will prove beneficial in terms of efficiency. A sample
statement is a basic SELECT all query that would look something like this:
SELECT *
FROM <tablename>;
But the
execution will involve an index range scan rather than a complete table scan
for better results. Otherwise, you may have to performance
tune SQL query or queries. Another interesting thing to note is
regarding the calculation of the clustering factor. It is done on the basis of
the data present in the index, and the table is not used as a reference in any
way.









Comments